🔊 생성형 AI모델 Diff-SVC 기반의 음성변환/합성 시스템 개발
- 팀 구성 : 인공지능 2, ios 1, server 1
- 개발 기간 : 2023.09~2023.12 (3개월)
기술 스택
- SpringBoot 2.7.14
- spring data jpa
- openapi 1.7.8
- spring security
- postgresql 14.7
- azure database for postgresql
- azure blob
- azure vm
- google tts api
- docker
- github action
1. 프로젝트 개요
Diff-SVC는 녹음된 음성을 다른 사람의 목소리로 변환하는 데 사용되는 인공지능 기술입니다. 이 기술은 음성 합성과 목소리 변환 분야에서 기존의 방법들보다 향상된 기능을 보여주었으며, 여러 매체에서 두각을 나타내고는 하였습니다. 해당 기술을 활용하여 서비스를 개발하는 것은 기술 적용 분야에 있어서 하나의 도전이고, 이러한 점에서 창의학기제의 목표 지향에 부합한다고 생각하였습니다. 사용자가 원하는 목소리로 음성을 변환하는 서비스 구현을 위해, 복합적인 모델 구조를 설계하고 개발을 진행하였으며, 모델 학습이 완료된 후에는 음성변환 시스템으로 변환된 음성에 학습된 모델을 적용하여 사용자가 원하는 인물의 목소리 특성이 정확하게 반영되도록 하였습니다. 또한 인공지능단에서 개발한 모델을 서비스할 수 있도록 클라이언트-서버 아키텍처로 설계하여 개발을 진행하였습니다.
2. 프로젝트에서 역할 - 팀장, DevOps
- 프로젝트의 아키텍처 설계
- 인프라 구축 : Azure VM, docker를 사용한 컨테이너화, Github Action을 통한 CICD 파이프라인 구축
- 데이터베이스 구축 및 관리(PostgreSQL) : azure database for postgresql, azure blob
- Springboot를 사용한 API 개발 : 기본적인 통신작업 및 Google TTS API 도입
- 역할 별 이슈 종합 및 개발 진행 상황 관리 : 직접 시퀀스 다이어그램을 제작하고, 프론트단 및 인공지능단의 개발 과정과 이슈 사항을 종합하여 기간 내 프로젝트가 완성될 수 있도록 일정 수시로 조정함.
🔍 주요 문제점
데이터 전처리 및 학습 과정의 어려움
- 음성 데이터셋 확보 시 최소 1시간 분량의 고품질(잡음 없는) 음성이 필요함.
- 음성 데이터를 12~15초로 세분화(segmentation) 후에만 학습 가능.
- 전처리된 데이터셋을 24시간 이상 학습시켜야 모델 사용 가능.
🛠 해결 방안
- 데이터 수집 전략 개선
- 공인을 대상으로 데이터 수집하여 데이터 확보 용이성 강화.
- 부족한 데이터는 데이터 증강(Data Augmentation) 기법을 활용.
- 데이터 증강(DiffWave 모델 활용)
- DiffWave 음성 생성 모델을 사용해 기존 음성에 random noise를 추가해 새로운 음성 데이터 생성.
- 데이터 다양성 확보 및 학습 효율성 향상.
* DiffWave 논문 : https://arxiv.org/abs/2009.09761
DiffWave: A Versatile Diffusion Model for Audio Synthesis
In this work, we propose DiffWave, a versatile diffusion probabilistic model for conditional and unconditional waveform generation. The model is non-autoregressive, and converts the white noise signal into structured waveform through a Markov chain with a
arxiv.org
제목: DIFFWAVE: A Versatile Diffusion Model for Audio Synthesis
저자: Zhifeng Kong, Wei Ping, Jiaji Huang, Kexin Zhao, Bryan Catanzaro
소속: UCSD, NVIDIA, Baidu Research
발표: ICLR 2021
3. 시퀀스 다이어그램
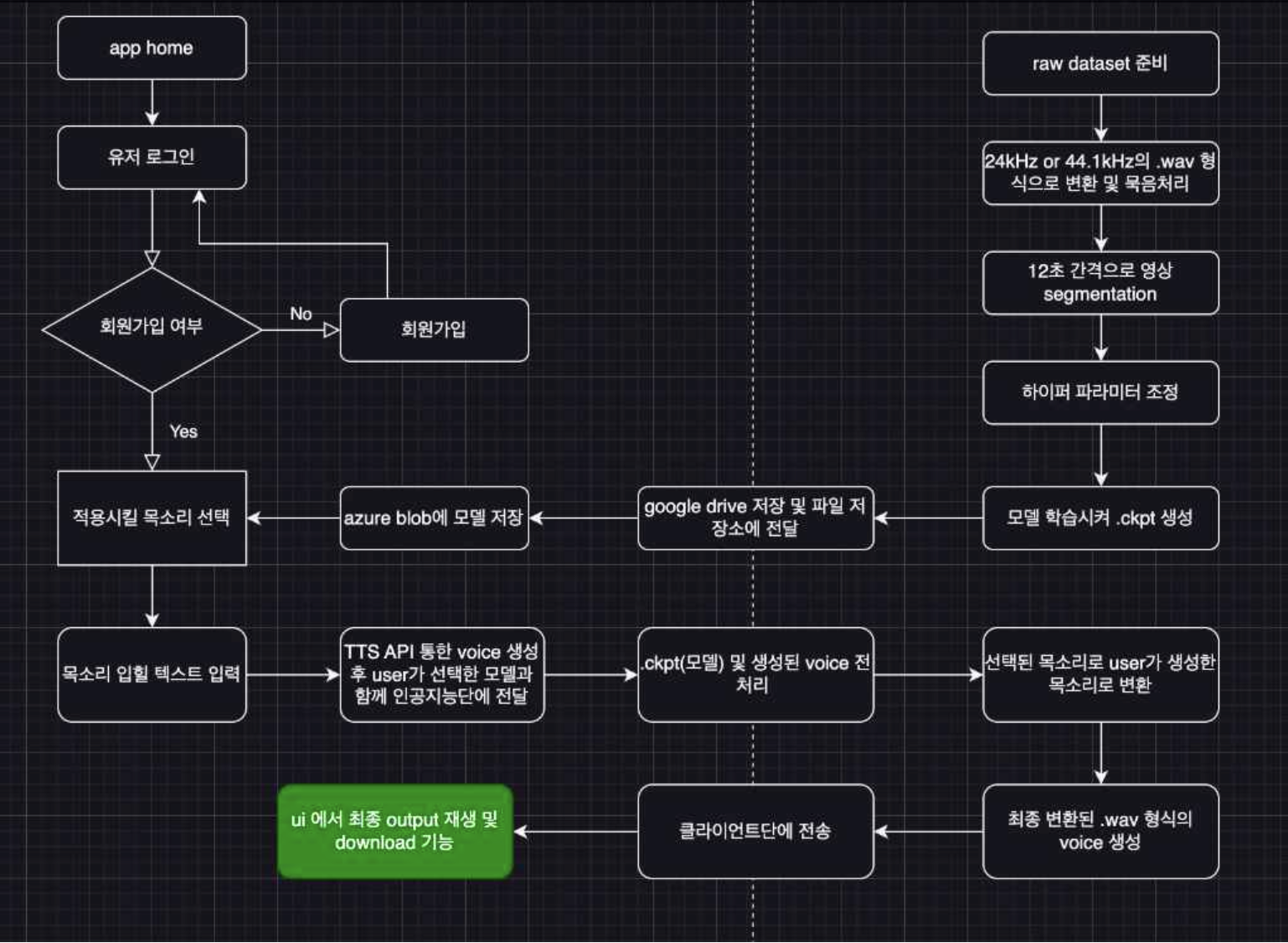
3. 서비스 아키텍처
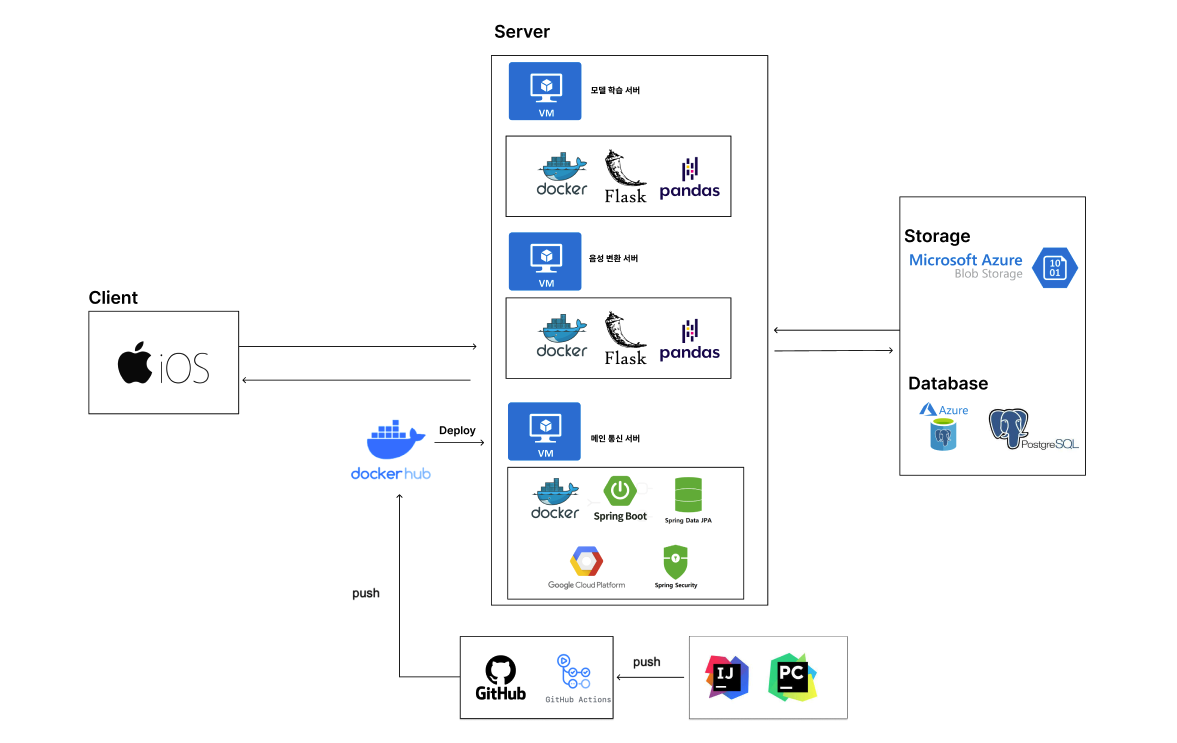
4. 시현 영상
5. 기대 효과
(1) 개인화 음성변환/합성 서비스 제공
Diff-SVC 기반의 개인화 음성변환 및 합성 시스템은 사용자가 원하는 목소리로 음성을 변환하거나 합성해주는 서비스를 제공합니다. 이를 통해 사용자는 자신이 선호하는 음성으로 다양한 콘텐츠를 청취할 수 있어, 보다 몰입감 있는 경험을 할 수 있습니다.
(2) 다양한 산업 분야로의 확장 가능성
개인화 음성변환 및 합성 기술은 오디오북, 콘텐츠 제작, 더빙, 가상 비서, 게임 캐릭터 음성 등 다양한 분야에 적용될 수 있습니다. 이러한 분야와 콘텐츠 산업의 결합은 시장 확대와 함께 서비스의 상품화 가능성을 높여, 새로운 비즈니스 모델 창출로 이어질 수 있습니다.
(3) 정보 접근성 향상 및 사회적 가치 실현
음성변환 기술을 활용해 다양한 목소리로 콘텐츠를 제공함으로써 시각 장애인이나 독서에 어려움을 겪는 사람들이 원하는 목소리로 정보를 접할 수 있습니다. 이는 정보 접근성을 높여 사회적 가치 실현에 기여할 수 있습니다.
6. 최종성과 발표
7. 프로젝트를 진행하면서 느낀 점
해당 프로젝트는 음성 변환 기술인 Diffusion Singing Voice Conversion(Diff-SVC)을 활용하여, 사용자가 특정 공인의 목소리로 노래하거나 말하는 음성 콘텐츠를 생성할 수 있는 플랫폼으로서 엔터테이너적인 요소만 집중하여 기획된 프로젝트였다. 기획을 하며 가장 큰 문제가 있었는데, 해당 프로젝트를 배포할 때 저작권 문제가 큰 이슈가 될 수 있다는 점이었다. 만약 어떠한 공인의 음성 데이터를 허가 없이 학습 후 사용하는 것은 저작권을 위반하는 것이라고 생각하였다. 이에 대한 방안으로 소속사에 소속된 공인의 목소리를 사용하기 위한 저작권 협의를 소속사와 진행하는 것이었다. 그러면 저작권 문제 뿐만 아니라, 수익구조에 관한 것도 해결할 수 있다고 생각하였다. 하지만 앞서 말한 것과 같이 진행되면 프로젝트의 사이즈가 본래 기획한 것 보다 훨씬 커지기에 실제로 진행하는 것은 현실적으로 어렵다고 느껴졌다. 즉 창업의 영역으로 넘어간다고 생각했기 때문에 이를 확장하기에는 팀원 모두가 부담스럽게 느껴졌다. 팀원 모두 각자의 목표가 있는데 이 목표가 전부 부합하지 않았기 때문에 실제로 확장하지 못하였고, 이에 대한 아쉬움이 남는 프로젝트였다.